Understanding AWS Lambda and API Gateway Timeouts
When building serverless applications with AWS Lambda and API Gateway, one of the most common sources of confusion is handling timeouts — and how the architecture impacts them.
If you’ve ever received a vague "504 Gateway Timeout" or "Task timed out after X seconds" message, this post breaks down why that happens and how to fix it.
1. The root cause: Timeouts at multiple layers
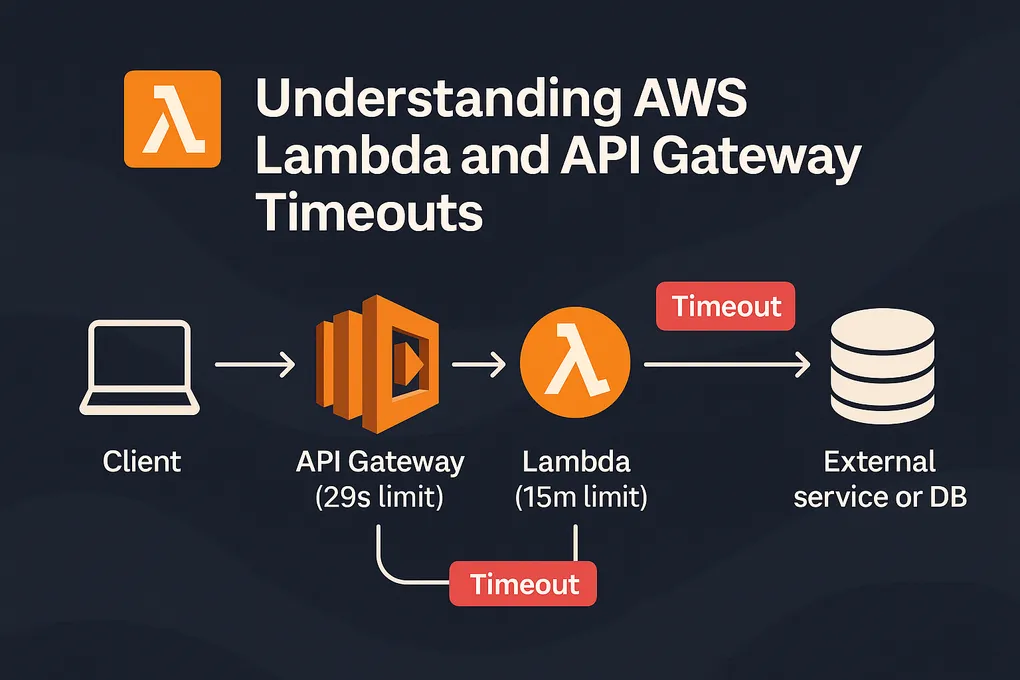
When you deploy a Lambda function behind API Gateway, both services have their own timeout settings:
- API Gateway timeout — maximum 29 seconds (hard AWS limit).
- Lambda function timeout — configurable up to 15 minutes.
That means even if your Lambda can run for 5 minutes, API Gateway will stop waiting after 29 seconds.
The client disconnects, and the request appears to have failed — even though your Lambda might still be running.
2. Common scenarios where this happens
Here are a few typical cases where engineers hit timeouts:
- Heavy data processing or file uploads directly through API Gateway.
- Synchronous workflows (like report generation) instead of async queues.
- Unoptimized external API calls or database queries.
- Misaligned timeout settings between Lambda, API Gateway, and SDK retries.
3. Architecture patterns to prevent timeouts
Here are a few practical ways to design around those limits:
🧩 1. Use asynchronous patterns
Offload long-running work to:
- SQS + Lambda consumer
- SNS → Lambda
- EventBridge scheduler or step functions
Then immediately return a 202 Accepted response with a job ID.
⚙️ 2. Use Step Functions for long workflows
If your process must run for minutes, Step Functions can orchestrate multiple Lambdas safely, handle retries, and keep your API Gateway response fast.
You can trigger the workflow asynchronously and poll its state later.
Example pattern:
- API Gateway → Lambda (start execution)
- Lambda → Step Function (run workflow)
- API Gateway immediately responds with a job ID
- Client queries a
/statusendpoint later
This pattern decouples user response time from processing time.
🚀 3. Optimize Lambda performance
Sometimes the best solution is simply faster execution.
Focus on:
- Cold start mitigation: use smaller dependencies, keep Lambdas warm, or use Provisioned Concurrency.
- Efficient data access: cache results in Redis or DynamoDB.
- Avoid network bottlenecks: use VPC endpoints only when needed — VPC-attached Lambdas are slower to initialize.
☁️ 4. Use direct integrations when possible
For lightweight operations (e.g., S3 uploads, DynamoDB writes), API Gateway can directly integrate with AWS services — no Lambda required.
This removes the function entirely and reduces latency, cost, and timeout risks.
4. Visualizing the request flow
Client │ ▼ API Gateway (29s hard limit) │ ▼ Lambda (up to 15 min) │ ▼ External service or DB
If any operation downstream exceeds ~29 seconds, API Gateway returns a 504, even if the Lambda is still running.
5. Real-world example
At CiiRUS, I recently helped refactor an API Gateway → Lambda → OpenAI API integration that would occasionally time out due to slow third-party responses.
We solved it by:
- Moving the OpenAI API calls to an asynchronous queue (SQS + Lambda).
- Having the frontend poll a /status endpoint until completion.
Result: no more API Gateway timeouts, and better transparency for users waiting on long operations.
6. Key takeaways
- API Gateway timeouts are capped at 29 seconds — you can’t change that.
- Design APIs to respond quickly, even if work continues asynchronously.
- Use Step Functions, queues, or events to manage long tasks.
- Always log and monitor timeout patterns using CloudWatch Metrics and X-Ray.
In short:
Timeouts aren’t a bug — they’re a signal that your architecture needs to scale asynchronously.
Once you start thinking in events instead of synchronous requests, serverless becomes much more powerful — and resilient.
🧠 If you enjoyed this post, you might like upcoming ones on AWS Lambda concurrency, cold starts, and cost optimization for high-volume SaaS systems.